全文检索-ElasticSearch 进阶检索
官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/7.5/getting-started-search.html
SearchAPI
ES 支持两种基本方式检索 :
- 一个是通过使用 REST request URI 发送搜索参数(uri+检索参数)
- 另一个是通过使用 REST request body 来发送它们(uri+请求体)
uri+检索参数
GET bank/_search?q=*&sort=account_number:asc
?后面表示检索条件
bank:表示在bank索引下;
_search:表示检索,固定写法;
q=*:表示查询所有;
sort=account_number:asc:表示按照account_number:asc升序排列
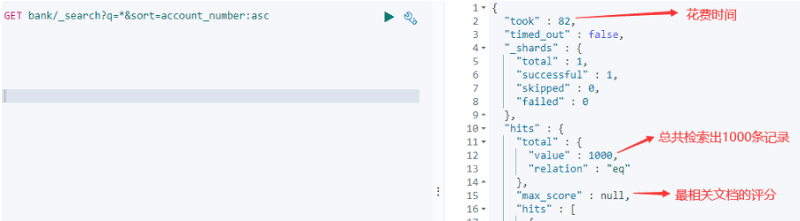
Elasticsearch 默认会分页返回10条数据,不会一下返回所有数据。
uri+请求体
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": "asc"
}
]
}
# query 查询条件
# sort 排序条件Query DSL
1.基本语法格式
{
QUERY_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}如果是针对某一个字段的查询
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}示例:
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance": "desc"
}
],
"from": 0,
"size": 5
}
// match_all 查询类型【代表查询所有的所有】,es中可以在query中组合非常多的查询类型完成复杂查询;
// 除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort,size
// from+size 限定,完成分页功能;从第几条数据开始,每页有多少数据。类似于mysql limt
// sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;
//from -size 表示从第一条记录,拿五条2.返回部分字段
"_source": ["field1","field2"]GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5,
"sort": [
{
"account_number": {
"order": "desc"
}
}
],
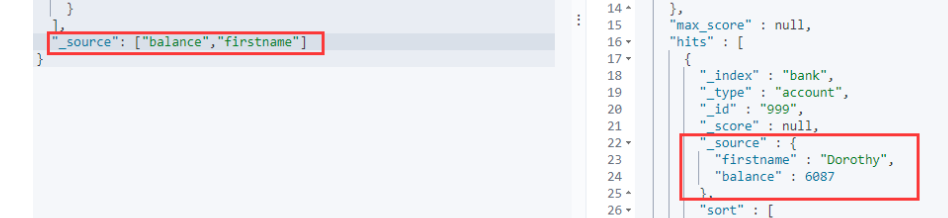
"_source": ["balance","firstname"] // 只返回balance和firstname字段
}
match【匹配查询】
精确查找——非字符串类型
GET bank/_search
{
"query": {
"match": {
"account_number": "20"
}
}
}
// 非字符串字段会精确匹配,查找匹配 account_number 为 20 的数据,非字符串类型推荐使用term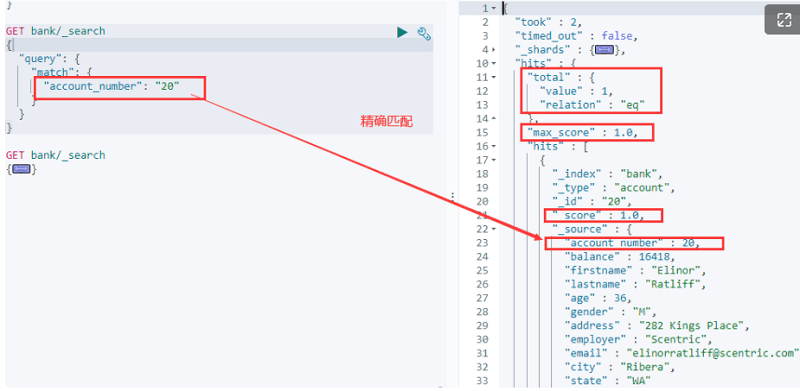
模糊查找-----字符串类型
GET bank/_search
{
"query": {
"match": {
"address": "Kings" // 字符串字段会模糊查询
}
}
}
GET bank/_search
{
"query": {
"match": {
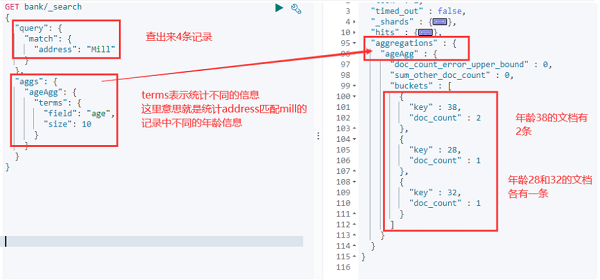
"address": "mill lane" // 匹配包含mill或lane的数据
}
}
}
# 全文检索最终会按照评分进行排序,会对检索条件进行分词匹配精确匹配——字符串类型
GET bank/_search
{
"query": {
"match": {
"address.keyword": "288 Mill Street"
}
}
}
# 查找 address 为 288 Mill Street 的数据。
# 这里的查找是精确查找,只有完全匹配时才会查找出存在的记录,
# 如果想模糊查询应该使用match_phrase 短语匹配
# 注意这里的address.keywordmatch_phrase【短语匹配】
之前通过match匹配的时候,es会自动分词,只要目标字段包含了分词都会计算相关性得分返回。
而match_phrase不会进行分词,会把查询条件作为完整短语进行匹配。
GET bank/_search
{
"query": {
"match_phrase": { "address": "mill road"}
}
}
# match_phrase:查出 address 中包含 mill road 的所有记录,并给出相关性得分
# match_phrase是对"mill road"整体进行模糊匹配multi_match【多字段匹配】
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill lopezo",
"fields": ["city","address"]
}
}
}
# select * from xxx where `state` like mill or `address` like mill or `state` like lopezo or `address` like lopezo
# city 或者 address 包含 millbool【复合查询】
GET bank/_search
{
"query": {
"bool": {
"must": [ # must:必须达到must所列举的所有条件。
{"match": {"gender": "M"}},
{"match": {"address": "mill"}}
],
"must_not": [ # 必须不匹配must_not所列举的所有条件
{"match": {"age": "18"}}
],
"should": [ #应该满足should所列举的条件,如果达到会增加相关文档的评分,并不会改变查询的结果
{"match": {"lastname": "Wallace"}}
]
}
}
}query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而去改变查询结果
filter 过滤
并不是所有的查询都需要产生分数,filter会对结果进行过滤,且不会计算相关性得分。(其作用和must相同,唯一区别就是不会计算相关性得分)
must_not 就可以看做是一个filter,它影响文档是否包含在结果中,但是不影响文档的评分。
GET bank/_search
{
"query": {
"bool": {
"must": [ // must会计算相关性得分
{"range": {
"age": {
"gte": 18,
"lte": 30
}
}}
]
}
}
}
GET bank/_search
{
"query": {
"bool": {
"filter": { // filter不会计算相关性得分
"range": {
"age": {
"gte": 18,
"lte": 30
}
}
}
}
}
}term【精确检索】
和match一样,匹配某个属性的值。全文检索字段用match,其他非text字段匹配用term。
GET /_search
{
"query": {
"term": {
"age": 28
}
}
}
// 查找年龄为28的用户数据
阅读剩余
版权声明:
作者:Tin
链接:https://www.tinstu.com/2604.html
文章版权归作者所有,未经允许请勿转载。
THE END